Assignment
1) Replace the embeddings of this session’s code with GloVe embeddings
2) Compare your results with this session’s code.
3) Upload to a public GitHub repo and proceed to Session 10 Assignment Solutions where these questions are asked:
1) Share the link to your README file’s public repo for this assignment. Expecting a minimum 500-word write-up on your learnings. Expecting you to compare your results with the code covered in the class. - 750 Points
2) Share the link to your main notebook with training logs - 250 Points
Solution
Task: English to French Translation using Glove Embeddings
| GitHub Link | Google Colab Link |
|---|---|
| Link to Code | Link to Code |

Architecture
Encoder
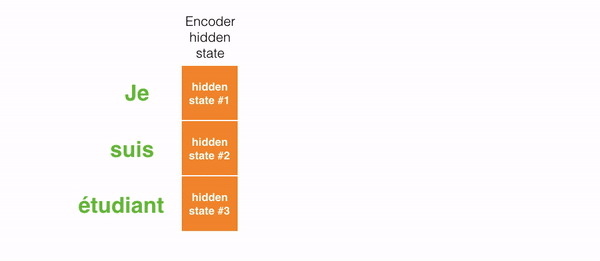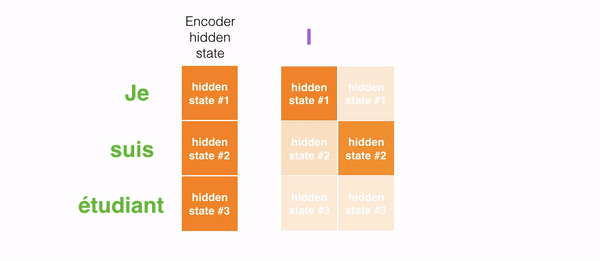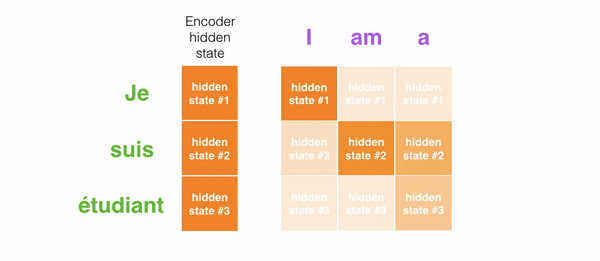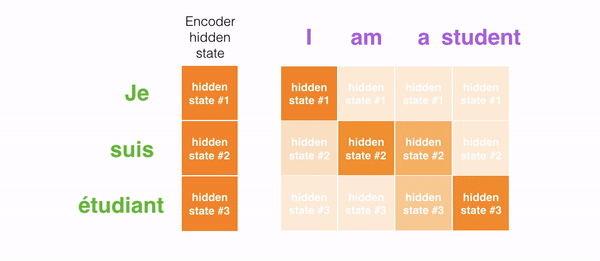
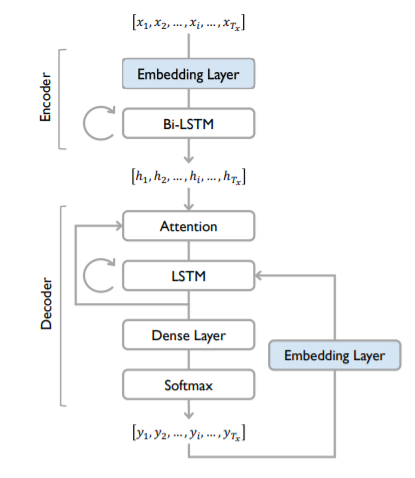
In encoder, an english sentence is given as input along with initial hidden state. The english input is converted into embeddings using Glove embedding layer. The embedded vector and initial hidden state are then passed to GRU which gives all hidden states as output. Instead of passing the last hidden state of the encoding stage, the encoder passes all the hidden states to the decoder because each hidden state corresponds to a particular word in the sentence.
Decoder

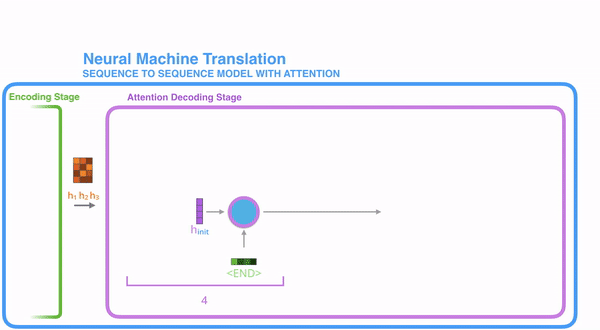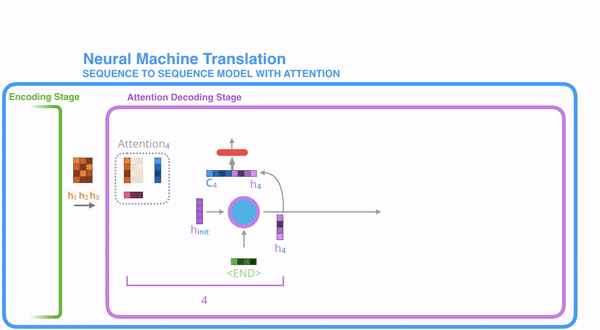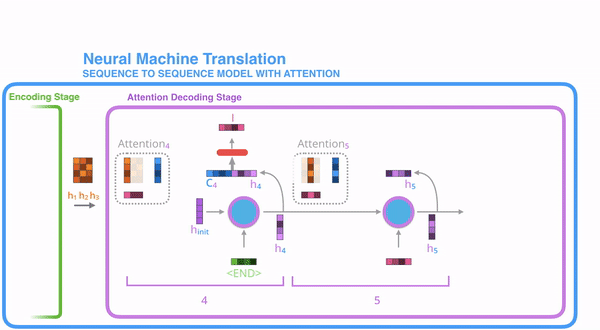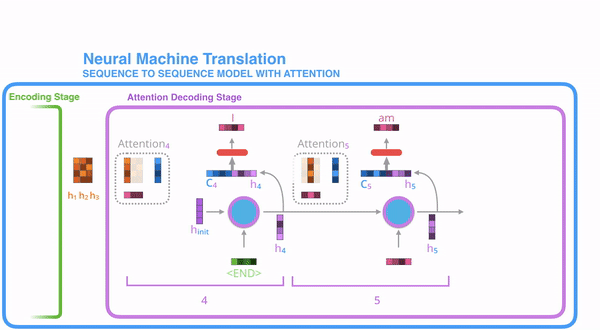
Training
Teacher Forcing
Teacher Forcing is a training technique to quickly and efficiently train recurrent neural network models that use the ground truth from a prior time step as input. In sequence prediction models, the output from the last time step y(t-1) as input for the model at the current time step X(t). It is used in tasks such as Machine Translation, Caption Generation, Text Summarization, etc.
The problem with this training approach is that since the model is in learning phase, the output generated by previous time step will not be accurate and so each successive steps would get affected. This is like learning subject A from a student who herself is learning subject A. This leads to slower convergence of the model and instability in the model.
Solution to this problem is instead of learning from a student, learning from teacher would give better esults. The teacher in this case would be the target values. Teacher forcing works by using the actual or expected output from the training dataset at the current time step y(t) as input in the next time step X(t+1), rather than the output generated by the network(y_hat(t)).
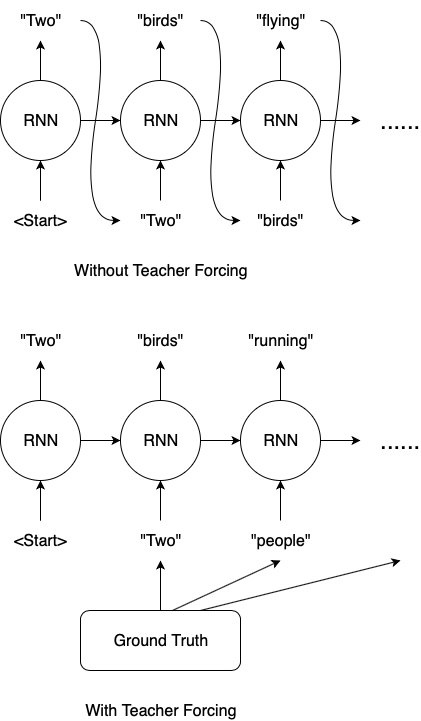
Consider above example. Target is Two people reading book. Since the 2nd word is incorrectly predicted as bird, in absence of teacher forcing, wrong word will go as input to next step. In teacher forcing, gound tructh people goes as input. Thus, model will learn better in teacher forcig.
Pros:
Training with Teacher Forcing converges faster. This is because in the early stages of training, the predictions of the model are very bad. If we do not use Teacher Forcing, the hidden states of the model will be updated by a sequence of wrong predictions, errors will accumulate, and it is difficult for the model to learn from that.
Cons:
During inference, since there is usually no ground truth available, the model will need to feed its own previous prediction back to itself for the next prediction. Therefore there is a discrepancy between training and inference, and this might lead to poor model performance and instability. This is known as Exposure Bias.
Teacher Forcing with 50% probability is used here.
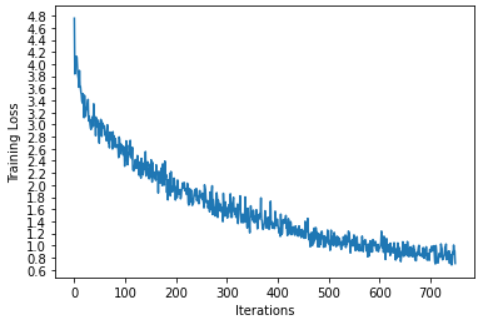
Training Logs
6m 27s (- 90m 22s) (5000 6%) 3.3636
12m 52s (- 83m 42s) (10000 13%) 2.7571
19m 19s (- 77m 17s) (15000 20%) 2.3692
25m 46s (- 70m 51s) (20000 26%) 2.1001
32m 12s (- 64m 24s) (25000 33%) 1.8624
38m 39s (- 57m 59s) (30000 40%) 1.6947
45m 7s (- 51m 34s) (35000 46%) 1.5429
51m 33s (- 45m 6s) (40000 53%) 1.4161
58m 0s (- 38m 40s) (45000 60%) 1.2803
64m 24s (- 32m 12s) (50000 66%) 1.1457
70m 52s (- 25m 46s) (55000 73%) 1.0729
77m 18s (- 19m 19s) (60000 80%) 0.9919
83m 46s (- 12m 53s) (65000 86%) 0.9408
90m 13s (- 6m 26s) (70000 93%) 0.8829
96m 40s (- 0m 0s) (75000 100%) 0.8556
Visualization
Training Graph
Attention Visualization
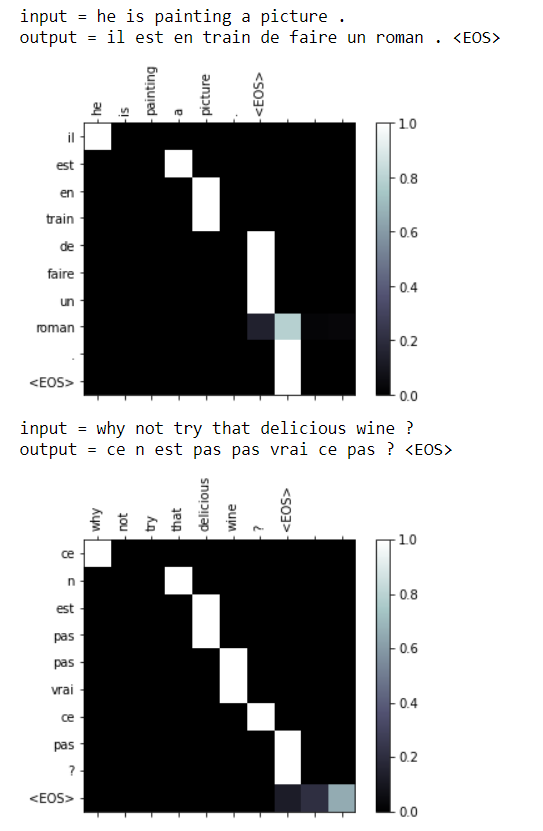
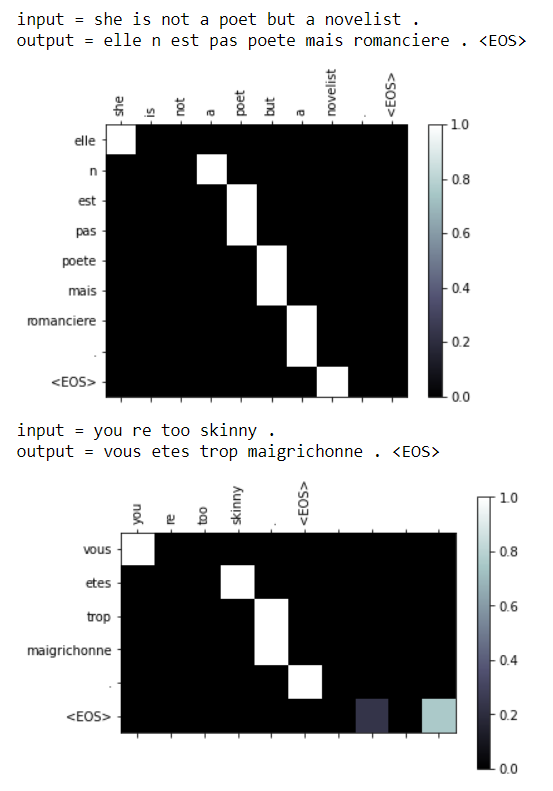
Evaluation
> she is being blackmailed by him .
= il exerce sur elle du chantage .
< elle va beaucoup lui lui . <EOS>
> you re very religious aren t you ?
= vous etes tres religieuses n est ce pas ?
< vous etes tres religieux n est ce pas ? <EOS>
> he is on the team .
= il fait partie de l equipe .
< il est partie de la equipe . <EOS>
> you re the leader .
= c est vous la chef .
< vous etes la chef chef . <EOS>
> you are too young to travel alone .
= vous etes trop jeunes pour voyager seuls .
< vous etes trop jeune pour voyager seul . <EOS>
> you aren t supposed to swim here .
= tu n es pas cense nager ici .
< vous n etes pas censees nager ici . <EOS>
> he s no saint .
= il n est pas un saint .
< ce n est pas un saint . <EOS>
> you re a woman now .
= vous etes desormais une femme .
< vous etes une femme maintenant . <EOS>
> we re surprised .
= nous sommes surprises .
< nous sommes surpris . <EOS>
> we re open tomorrow .
= nous sommes ouverts demain .
< nous sommes ouverts demain . <EOS>
Comparison with French-English Translator without Glove Embedding
| French-English without Glove | English-French with Glove 300 | English-French with Glove 50 | |
|---|---|---|---|
Hidden Dimension Size |
256 |
300 |
50 |
Link to Code |
Colab |
GitHub Colab |
GitHub Colab |
Training Logs |
1m 37s (- 22m 51s) (5000 6%) 2.8698 3m 10s (- 20m 41s) (10000 13%) 2.2560 4m 44s (- 18m 59s) (15000 20%) 1.9696 6m 18s (- 17m 21s) (20000 26%) 1.7177 7m 52s (- 15m 45s) (25000 33%) 1.4991 9m 26s (- 14m 10s) (30000 40%) 1.3369 11m 0s (- 12m 34s) (35000 46%) 1.2026 12m 34s (- 11m 0s) (40000 53%) 1.0701 14m 9s (- 9m 26s) (45000 60%) 0.9826 15m 43s (- 7m 51s) (50000 66%) 0.9066 17m 18s (- 6m 17s) (55000 73%) 0.7882 18m 53s (- 4m 43s) (60000 80%) 0.7265 20m 28s (- 3m 9s) (65000 86%) 0.6788 22m 3s (- 1m 34s) (70000 93%) 0.5923 23m 38s (- 0m 0s) (75000 100%) 0.5424 |
6m 27s (- 90m 22s) (5000 6%) 3.3636 12m 52s (- 83m 42s) (10000 13%) 2.7571 19m 19s (- 77m 17s) (15000 20%) 2.3692 25m 46s (- 70m 51s) (20000 26%) 2.1001 32m 12s (- 64m 24s) (25000 33%) 1.8624 38m 39s (- 57m 59s) (30000 40%) 1.6947 45m 7s (- 51m 34s) (35000 46%) 1.5429 51m 33s (- 45m 6s) (40000 53%) 1.4161 58m 0s (- 38m 40s) (45000 60%) 1.2803 64m 24s (- 32m 12s) (50000 66%) 1.1457 70m 52s (- 25m 46s) (55000 73%) 1.0729 77m 18s (- 19m 19s) (60000 80%) 0.9919 83m 46s (- 12m 53s) (65000 86%) 0.9408 90m 13s (- 6m 26s) (70000 93%) 0.8829 96m 40s (- 0m 0s) (75000 100%) 0.8556 |
1m 57s (- 27m 22s) (5000 6%) 3.7662 3m 52s (- 25m 10s) (10000 13%) 3.2280 5m 47s (- 23m 10s) (15000 20%) 3.0531 7m 43s (- 21m 15s) (20000 26%) 2.9402 9m 39s (- 19m 18s) (25000 33%) 2.8136 11m 34s (- 17m 22s) (30000 40%) 2.7815 13m 29s (- 15m 25s) (35000 46%) 2.6704 15m 25s (- 13m 30s) (40000 53%) 2.5774 17m 20s (- 11m 33s) (45000 60%) 2.5704 19m 16s (- 9m 38s) (50000 66%) 2.5075 21m 11s (- 7m 42s) (55000 73%) 2.4544 23m 5s (- 5m 46s) (60000 80%) 2.4038 25m 1s (- 3m 50s) (65000 86%) 2.3848 26m 56s (- 1m 55s) (70000 93%) 2.3420 28m 50s (- 0m 0s) (75000 100%) 2.3033 |
Observations |
Better loss when comared with 50 and 300 glove dimension pretrained networks. Need to compare with 200 glove embedding to compare performance. |
When compared with no embeddings, we see higher loss because hidden dimension was increased from 256 to 300. Although the encoder has to learn less because of pretrained weights, the decoder's learning task is increased due to additional hidden dimension. It has to capture more context. |
When compared with no embeddings, we see higher loss because hidden dimension was decreased from 256 to 50. Lesser context is captured by the embedding dimension and so lesser information is captured by the model. Thus, the model's is nt capable to learn the translation. |
Improvements
1) LSTM and Bi-directional LSTMs can be used instead of RNN. (Reference paper)
2) Adam optimizer can be used instead of SGD