BackPropagation And Architecture Basics
Part 1) Backpropagation
GitHub Link to Neural Network Training excel sheet
Major Steps in NN Training
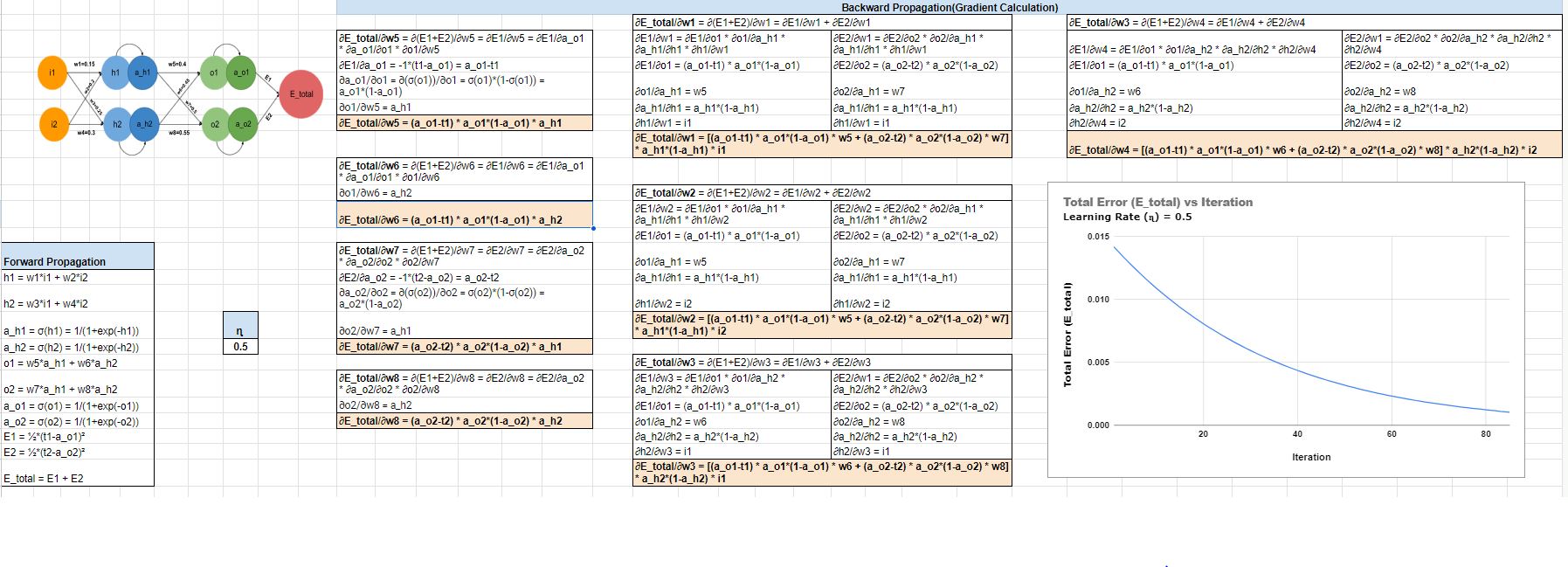
Suppose we have the below network:
1) Initialization of Neural Network
Randomly initializing weights [w1,….,w8] and Learning Rate lr.
2) For each iteration, below steps are performed:
A) Forward Propagation
For the above network, output will be calculated using the below formulae:
h1 = w1*i1 + w2*i2
h2 = w3*i1 + w4*i2
a_h1 = σ(h1) = 1/(1+exp(-h1))
a_h2 = σ(h2) = 1/(1+exp(-h2))
o1 = w5*a_h1 + w6*a_h2
o2 = w7*a_h1 + w8*a_h2
a_o1 = σ(o1) = 1/(1+exp(-o1))
a_o2 = σ(o2) = 1/(1+exp(-o2))
B) Backpropagation
I) Using the generated output and target, error is calculated.
For above network, L2 error is calculated as shown below:
E1 = ½*(t1-a_o1)²
E2 = ½*(t2-a_o2)²
E_total = E1 + E2
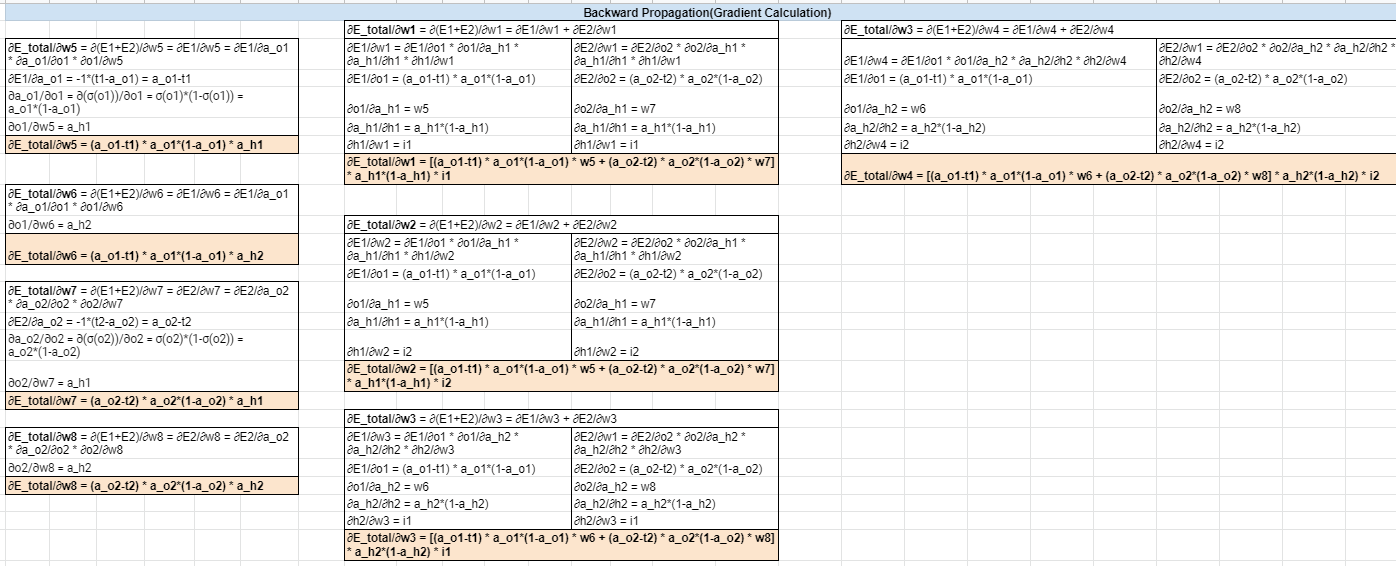
II) Each of the weight in the network is updated as follows:
i) Error gradient with respect to the specific weight(∂Error/∂wi) is calculated. Negative error indicates the direction in which the error can be minimized by updatig the specific weight.
Example:- For w5
∂E_total/∂w5 = ∂(E1+E2)/∂w5 = ∂E1/∂w5 = ∂E1/∂a_o1 * ∂a_o1/∂o1 * ∂o1/∂w5
∂E1/∂a_o1 = -1*(t1-a_o1) = a_o1-t1
∂a_o1/∂o1 = ∂(σ(o1))/∂o1 = σ(o1)*(1-σ(o1)) = a_o1*(1-a_o1)
∂o1/∂w5 = a_h1
Thus, it becomes
∂E_total/∂w5 = (a_o1-t1) * a_o1*(1-a_o1) * a_h1
ii) Weight is updated using:
wij+1 = wij - ɳ * ∂Error/∂wij
where i is the weight index,
j is the iteration number
For above network, below are the error gradients with respect to weights calculated using chain formula.
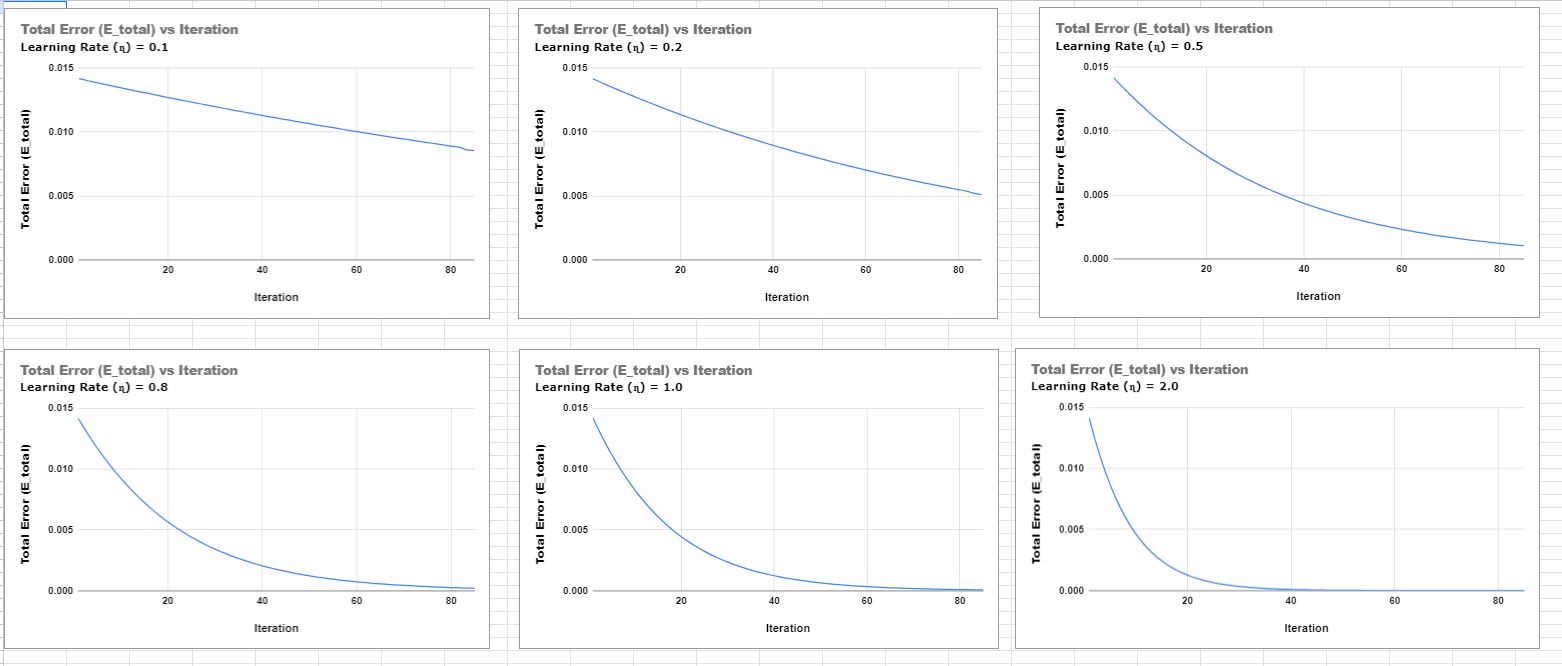
Error Graphs for various learning rates
Part 2) Architecture Basics
| Code Link |
|---|
| GitHub |
| Google Colab |
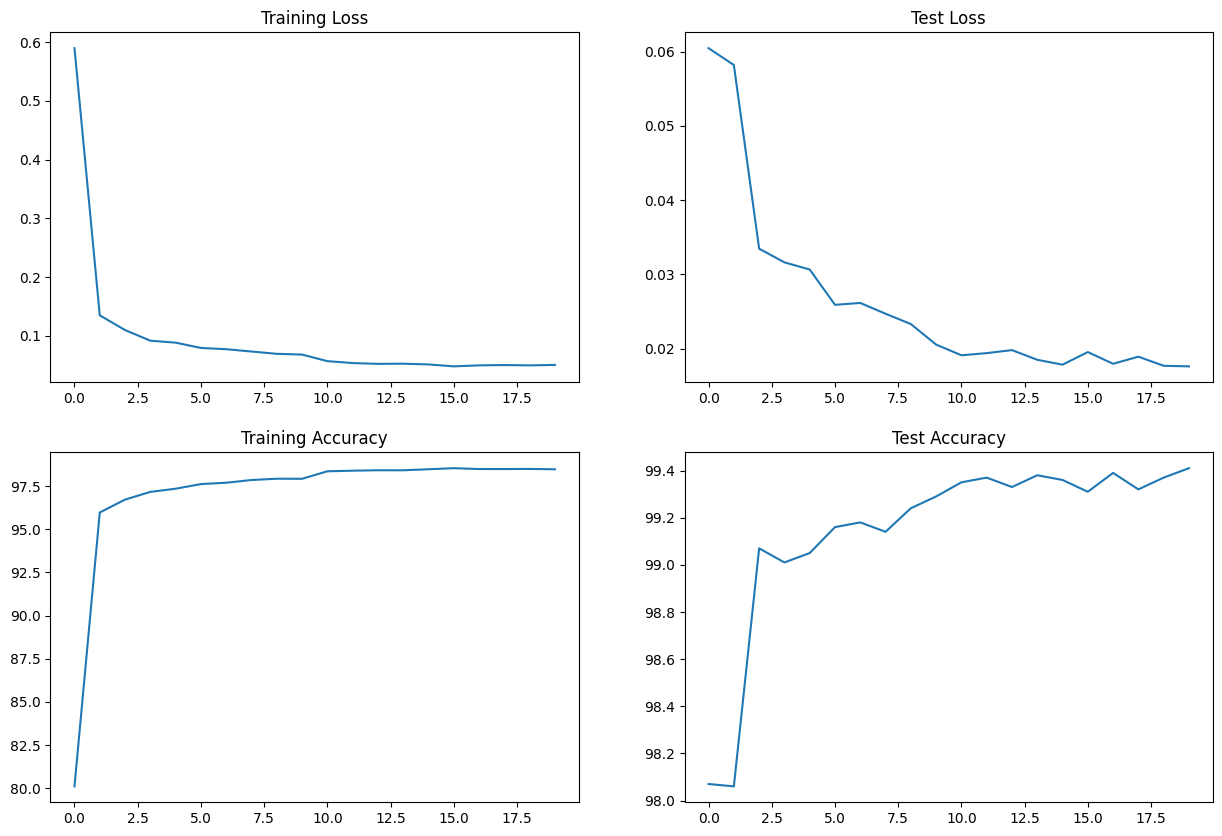
Best/Final Test Accuracy: 99.41 %
Model Architecture
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 16, 26, 26] 144
ReLU-2 [-1, 16, 26, 26] 0
BatchNorm2d-3 [-1, 16, 26, 26] 32
Dropout-4 [-1, 16, 26, 26] 0
Conv2d-5 [-1, 24, 24, 24] 3,456
ReLU-6 [-1, 24, 24, 24] 0
BatchNorm2d-7 [-1, 24, 24, 24] 48
Dropout-8 [-1, 24, 24, 24] 0
Conv2d-9 [-1, 10, 24, 24] 240
MaxPool2d-10 [-1, 10, 12, 12] 0
Conv2d-11 [-1, 14, 10, 10] 1,260
ReLU-12 [-1, 14, 10, 10] 0
BatchNorm2d-13 [-1, 14, 10, 10] 28
Dropout-14 [-1, 14, 10, 10] 0
Conv2d-15 [-1, 16, 8, 8] 2,016
ReLU-16 [-1, 16, 8, 8] 0
BatchNorm2d-17 [-1, 16, 8, 8] 32
Dropout-18 [-1, 16, 8, 8] 0
Conv2d-19 [-1, 16, 6, 6] 2,304
ReLU-20 [-1, 16, 6, 6] 0
BatchNorm2d-21 [-1, 16, 6, 6] 32
Dropout-22 [-1, 16, 6, 6] 0
AvgPool2d-23 [-1, 16, 1, 1] 0
Conv2d-24 [-1, 16, 1, 1] 256
Conv2d-25 [-1, 32, 1, 1] 512
Linear-26 [-1, 10] 330
================================================================
Total params: 10,690
Trainable params: 10,690
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.90
Params size (MB): 0.04
Estimated Total Size (MB): 0.94
----------------------------------------------------------------
Training and Testing
Logs
Adjusting learning rate of group 0 to 1.0000e-02.
Epoch 1
Train: Loss=0.3845 Batch_id=937 Accuracy=80.10: 100%|██████████| 938/938 [00:39<00:00, 23.63it/s]
Test set: Average loss: 0.0605, Accuracy: 9807/10000 (98.07%)
Adjusting learning rate of group 0 to 1.0000e-02.
Epoch 2
Train: Loss=0.1039 Batch_id=937 Accuracy=95.97: 100%|██████████| 938/938 [00:31<00:00, 30.12it/s]
Test set: Average loss: 0.0582, Accuracy: 9806/10000 (98.06%)
Adjusting learning rate of group 0 to 1.0000e-02.
Epoch 3
Train: Loss=0.3055 Batch_id=937 Accuracy=96.72: 100%|██████████| 938/938 [00:31<00:00, 29.44it/s]
Test set: Average loss: 0.0334, Accuracy: 9907/10000 (99.07%)
Adjusting learning rate of group 0 to 1.0000e-02.
Epoch 4
Train: Loss=0.0642 Batch_id=937 Accuracy=97.17: 100%|██████████| 938/938 [00:33<00:00, 28.37it/s]
Test set: Average loss: 0.0316, Accuracy: 9901/10000 (99.01%)
Adjusting learning rate of group 0 to 1.0000e-02.
Epoch 5
Train: Loss=0.0445 Batch_id=937 Accuracy=97.35: 100%|██████████| 938/938 [00:31<00:00, 29.76it/s]
Test set: Average loss: 0.0306, Accuracy: 9905/10000 (99.05%)
Adjusting learning rate of group 0 to 1.0000e-02.
Epoch 6
Train: Loss=0.2260 Batch_id=937 Accuracy=97.62: 100%|██████████| 938/938 [00:31<00:00, 30.21it/s]
Test set: Average loss: 0.0259, Accuracy: 9916/10000 (99.16%)
Adjusting learning rate of group 0 to 1.0000e-02.
Epoch 7
Train: Loss=0.1017 Batch_id=937 Accuracy=97.69: 100%|██████████| 938/938 [00:31<00:00, 29.83it/s]
Test set: Average loss: 0.0261, Accuracy: 9918/10000 (99.18%)
Adjusting learning rate of group 0 to 1.0000e-02.
Epoch 8
Train: Loss=0.0116 Batch_id=937 Accuracy=97.85: 100%|██████████| 938/938 [00:32<00:00, 29.27it/s]
Test set: Average loss: 0.0247, Accuracy: 9914/10000 (99.14%)
Adjusting learning rate of group 0 to 1.0000e-02.
Epoch 9
Train: Loss=0.0053 Batch_id=937 Accuracy=97.93: 100%|██████████| 938/938 [00:31<00:00, 29.97it/s]
Test set: Average loss: 0.0233, Accuracy: 9924/10000 (99.24%)
Adjusting learning rate of group 0 to 1.0000e-02.
Epoch 10
Train: Loss=0.1205 Batch_id=937 Accuracy=97.92: 100%|██████████| 938/938 [00:31<00:00, 30.02it/s]
Test set: Average loss: 0.0205, Accuracy: 9929/10000 (99.29%)
Adjusting learning rate of group 0 to 1.0000e-03.
Epoch 11
Train: Loss=0.1305 Batch_id=937 Accuracy=98.36: 100%|██████████| 938/938 [00:31<00:00, 29.66it/s]
Test set: Average loss: 0.0191, Accuracy: 9935/10000 (99.35%)
Adjusting learning rate of group 0 to 1.0000e-03.
Epoch 12
Train: Loss=0.1472 Batch_id=937 Accuracy=98.39: 100%|██████████| 938/938 [00:31<00:00, 29.53it/s]
Test set: Average loss: 0.0194, Accuracy: 9937/10000 (99.37%)
Adjusting learning rate of group 0 to 1.0000e-03.
Epoch 13
Train: Loss=0.1252 Batch_id=937 Accuracy=98.42: 100%|██████████| 938/938 [00:31<00:00, 30.06it/s]
Test set: Average loss: 0.0198, Accuracy: 9933/10000 (99.33%)
Adjusting learning rate of group 0 to 1.0000e-03.
Epoch 14
Train: Loss=0.0487 Batch_id=937 Accuracy=98.42: 100%|██████████| 938/938 [00:32<00:00, 29.13it/s]
Test set: Average loss: 0.0185, Accuracy: 9938/10000 (99.38%)
Adjusting learning rate of group 0 to 1.0000e-03.
Epoch 15
Train: Loss=0.0031 Batch_id=937 Accuracy=98.48: 100%|██████████| 938/938 [00:31<00:00, 29.94it/s]
Test set: Average loss: 0.0178, Accuracy: 9936/10000 (99.36%)
Adjusting learning rate of group 0 to 1.0000e-03.
Epoch 16
Train: Loss=0.0247 Batch_id=937 Accuracy=98.54: 100%|██████████| 938/938 [00:31<00:00, 29.47it/s]
Test set: Average loss: 0.0195, Accuracy: 9931/10000 (99.31%)
Adjusting learning rate of group 0 to 1.0000e-03.
Epoch 17
Train: Loss=0.0082 Batch_id=937 Accuracy=98.49: 100%|██████████| 938/938 [00:31<00:00, 29.69it/s]
Test set: Average loss: 0.0179, Accuracy: 9939/10000 (99.39%)
Adjusting learning rate of group 0 to 1.0000e-03.
Epoch 18
Train: Loss=0.0014 Batch_id=937 Accuracy=98.49: 100%|██████████| 938/938 [00:31<00:00, 30.16it/s]
Test set: Average loss: 0.0189, Accuracy: 9932/10000 (99.32%)
Adjusting learning rate of group 0 to 1.0000e-03.
Epoch 19
Train: Loss=0.0914 Batch_id=937 Accuracy=98.50: 100%|██████████| 938/938 [00:32<00:00, 29.14it/s]
Test set: Average loss: 0.0177, Accuracy: 9937/10000 (99.37%)
Adjusting learning rate of group 0 to 1.0000e-03.
Epoch 20
Train: Loss=0.0597 Batch_id=937 Accuracy=98.47: 100%|██████████| 938/938 [00:31<00:00, 29.40it/s]
Test set: Average loss: 0.0176, Accuracy: 9941/10000 (99.41%)
Adjusting learning rate of group 0 to 1.0000e-04.
Visualization