Session 8 - Batch Normalization and Regularization
Assignment
1) Change the dataset to CIFAR10
2) Make this network:
i) C1 C2 c3 P1 C3 C4 C5 c6 P2 C7 C8 C9 GAP C10
ii) Keep the parameter count less than 50000
iii) Try and add one layer to another
iv) Max Epochs is 20
3) You are making 3 versions of the above code (in each case achieve above 70% accuracy):
i) Network with Group Normalization
ii) Network with Layer Normalization
iii) Network with Batch Normalization
4) Share these details
i) Training accuracy for 3 models
ii) Test accuracy for 3 models
5) Find 10 misclassified images for the BN model, and show them as a 5x2 image matrix in 3 separately annotated images.
6) write an explanatory README file that explains:
i) what is your code all about
ii) your findings for normalization techniques
iii) add all your graphs
iv) your collection-of-misclassified-images
7) Upload your complete assignment on GitHub and share the link on LMS
Normalization Summary
| S.No. | Normalization Type | Results | Analysis | File Link |
|---|---|---|---|---|
| 1 | Batch Normalization | <ul><li>Best Train Accuracy - 82.59%</li><li> Best Test Accuracy - 79.60%</li><li> Test Accuracy - 79.39%</li><li>Total Parameters - 39,420</li></ul> | Better Performing Model with Lesser Parameters | Open |
| 2 | Group Normalization | <ul><li>Best Train Accuracy - 84.09%</li><li> Best Test Accuracy - 77.35%</li><li> Test Accuracy - 76.84%</li><li>Total Parameters - 40,360</li></ul> | The number of parameters increases on replacing batch normalization with group normalization. In order to keep the parameters within limits, the model capacity is decreased by decreasing number of channels. This leads to drop in model’s performance. | Open |
| 3 | Layer Normalization | <ul><li>Best Train Accuracy - 76.42% </li><li> Best Test Accuracy - 68.48%</li><li> Test Accuracy - 68.48%</li><li>Total Parameters - 55,612</li></ul> | The number of parameters increases a lot and it becomes difficult to constrain the parameters count within limit(50K). For this model’s capacity is decreased since not much scope for changing model’s structure. This leads to decrease in performance. | Open |
With CIFAR10 as the dataset: Among the 3 normalization, Batch Normalization gives the best performance with minimum parameters. This is because the number of parameters belonging to batch normalization is minimum among the 3 and so there is a scope of increasing model’s capacity.
1) Batch Normalization
Model Architecture

----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 16, 32, 32] 432
ReLU-2 [-1, 16, 32, 32] 0
BatchNorm2d-3 [-1, 16, 32, 32] 32
Dropout-4 [-1, 16, 32, 32] 0
Conv2d-5 [-1, 32, 32, 32] 4,608
ReLU-6 [-1, 32, 32, 32] 0
BatchNorm2d-7 [-1, 32, 32, 32] 64
Dropout-8 [-1, 32, 32, 32] 0
Conv2d-9 [-1, 16, 32, 32] 512
MaxPool2d-10 [-1, 16, 16, 16] 0
Conv2d-11 [-1, 24, 16, 16] 3,456
ReLU-12 [-1, 24, 16, 16] 0
BatchNorm2d-13 [-1, 24, 16, 16] 48
Dropout-14 [-1, 24, 16, 16] 0
Conv2d-15 [-1, 28, 16, 16] 6,048
ReLU-16 [-1, 28, 16, 16] 0
BatchNorm2d-17 [-1, 28, 16, 16] 56
Dropout-18 [-1, 28, 16, 16] 0
Conv2d-19 [-1, 32, 16, 16] 8,064
ReLU-20 [-1, 32, 16, 16] 0
BatchNorm2d-21 [-1, 32, 16, 16] 64
Dropout-22 [-1, 32, 16, 16] 0
Conv2d-23 [-1, 16, 16, 16] 512
MaxPool2d-24 [-1, 16, 8, 8] 0
Conv2d-25 [-1, 20, 8, 8] 2,880
ReLU-26 [-1, 20, 8, 8] 0
BatchNorm2d-27 [-1, 20, 8, 8] 40
Dropout-28 [-1, 20, 8, 8] 0
Conv2d-29 [-1, 26, 8, 8] 4,680
ReLU-30 [-1, 26, 8, 8] 0
BatchNorm2d-31 [-1, 26, 8, 8] 52
Dropout-32 [-1, 26, 8, 8] 0
Conv2d-33 [-1, 32, 8, 8] 7,488
ReLU-34 [-1, 32, 8, 8] 0
BatchNorm2d-35 [-1, 32, 8, 8] 64
Dropout-36 [-1, 32, 8, 8] 0
AvgPool2d-37 [-1, 32, 1, 1] 0
Conv2d-38 [-1, 10, 1, 1] 320
================================================================
Total params: 39,420
Trainable params: 39,420
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 2.50
Params size (MB): 0.15
Estimated Total Size (MB): 2.67
----------------------------------------------------------------
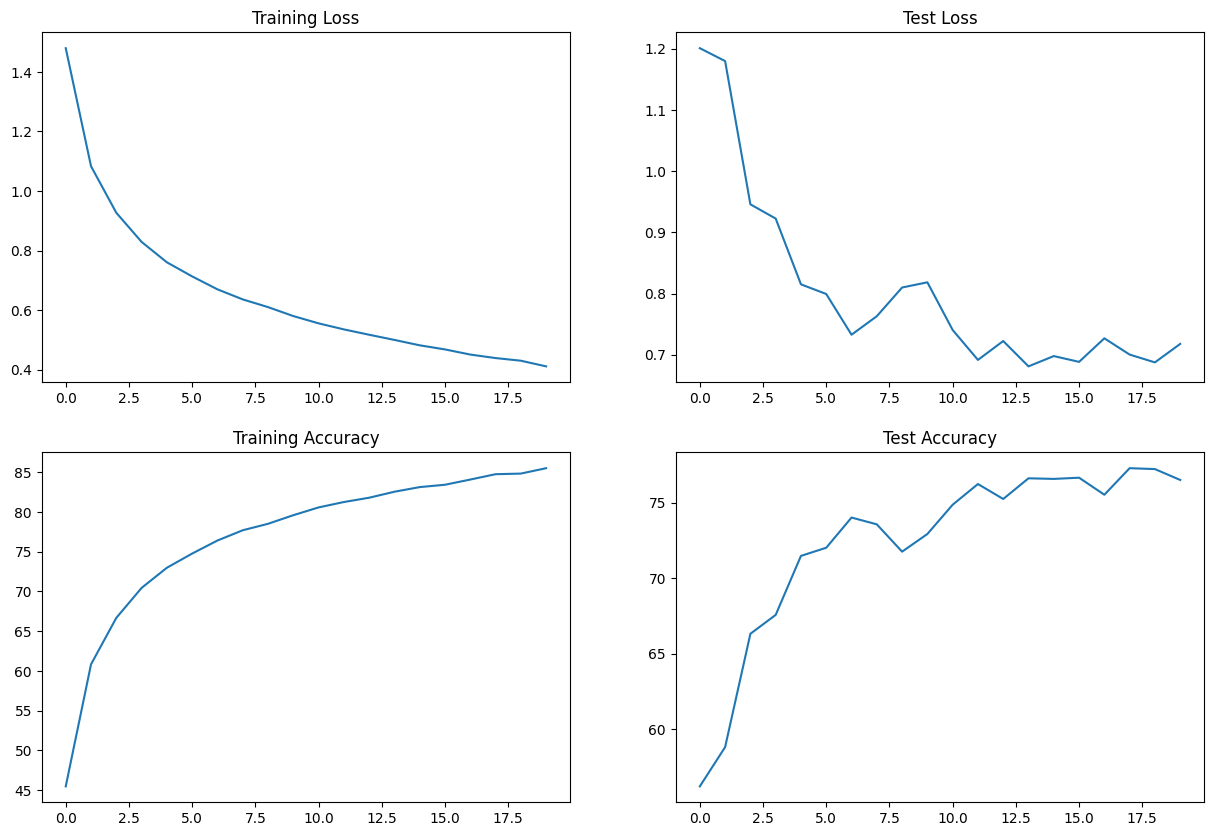
Results:
- Best Train Accuracy - 82.59%
- Best Test Accuracy - 79.60%
- Test Accuracy - 79.39%
- Total Parameters - 39,420
Train/Test Logs
Adjusting learning rate of group 0 to 1.0000e-01.
Epoch 1
Train: Loss=1.2112 Batch_id=390 Accuracy=49.44: 100%|██████████| 391/391 [00:21<00:00, 17.83it/s]Adjusting learning rate of group 0 to 1.0000e-01.
Test set: Average loss: 1.4187, Accuracy: 4908/10000 (49.08%)
Epoch 2
Train: Loss=0.8207 Batch_id=390 Accuracy=62.78: 100%|██████████| 391/391 [00:19<00:00, 20.27it/s]Adjusting learning rate of group 0 to 1.0000e-01.
Test set: Average loss: 0.9953, Accuracy: 6378/10000 (63.78%)
Epoch 3
Train: Loss=0.8988 Batch_id=390 Accuracy=67.42: 100%|██████████| 391/391 [00:18<00:00, 20.71it/s]Adjusting learning rate of group 0 to 1.0000e-01.
Test set: Average loss: 1.0392, Accuracy: 6375/10000 (63.75%)
Epoch 4
Train: Loss=1.0030 Batch_id=390 Accuracy=70.75: 100%|██████████| 391/391 [00:19<00:00, 19.72it/s]Adjusting learning rate of group 0 to 1.0000e-01.
Test set: Average loss: 0.8529, Accuracy: 6989/10000 (69.89%)
Epoch 5
Train: Loss=0.6245 Batch_id=390 Accuracy=72.43: 100%|██████████| 391/391 [00:20<00:00, 19.27it/s]Adjusting learning rate of group 0 to 1.0000e-01.
Test set: Average loss: 0.7671, Accuracy: 7314/10000 (73.14%)
Epoch 6
Train: Loss=0.7977 Batch_id=390 Accuracy=74.34: 100%|██████████| 391/391 [00:20<00:00, 19.40it/s]Adjusting learning rate of group 0 to 1.0000e-01.
Test set: Average loss: 0.8924, Accuracy: 6906/10000 (69.06%)
Epoch 7
Train: Loss=0.7652 Batch_id=390 Accuracy=75.23: 100%|██████████| 391/391 [00:19<00:00, 19.71it/s]Adjusting learning rate of group 0 to 1.0000e-01.
Test set: Average loss: 0.7223, Accuracy: 7506/10000 (75.06%)
Epoch 8
Train: Loss=0.7648 Batch_id=390 Accuracy=76.18: 100%|██████████| 391/391 [00:19<00:00, 19.71it/s]Adjusting learning rate of group 0 to 1.0000e-02.
Test set: Average loss: 0.7115, Accuracy: 7552/10000 (75.52%)
Epoch 9
Train: Loss=0.6539 Batch_id=390 Accuracy=79.76: 100%|██████████| 391/391 [00:19<00:00, 19.92it/s]Adjusting learning rate of group 0 to 1.0000e-02.
Test set: Average loss: 0.6143, Accuracy: 7865/10000 (78.65%)
Epoch 10
Train: Loss=0.8766 Batch_id=390 Accuracy=80.60: 100%|██████████| 391/391 [00:19<00:00, 19.67it/s]Adjusting learning rate of group 0 to 1.0000e-02.
Test set: Average loss: 0.6078, Accuracy: 7871/10000 (78.71%)
Epoch 11
Train: Loss=0.5852 Batch_id=390 Accuracy=80.99: 100%|██████████| 391/391 [00:20<00:00, 19.17it/s]Adjusting learning rate of group 0 to 1.0000e-02.
Test set: Average loss: 0.6078, Accuracy: 7879/10000 (78.79%)
Epoch 12
Train: Loss=0.7320 Batch_id=390 Accuracy=81.28: 100%|██████████| 391/391 [00:20<00:00, 19.20it/s]Adjusting learning rate of group 0 to 1.0000e-02.
Test set: Average loss: 0.6079, Accuracy: 7862/10000 (78.62%)
Epoch 13
Train: Loss=0.6432 Batch_id=390 Accuracy=81.33: 100%|██████████| 391/391 [00:20<00:00, 19.02it/s]Adjusting learning rate of group 0 to 1.0000e-02.
Test set: Average loss: 0.5993, Accuracy: 7896/10000 (78.96%)
Epoch 14
Train: Loss=0.6544 Batch_id=390 Accuracy=81.73: 100%|██████████| 391/391 [00:20<00:00, 19.25it/s]Adjusting learning rate of group 0 to 1.0000e-02.
Test set: Average loss: 0.5973, Accuracy: 7935/10000 (79.35%)
Epoch 15
Train: Loss=0.5268 Batch_id=390 Accuracy=81.69: 100%|██████████| 391/391 [00:20<00:00, 19.43it/s]Adjusting learning rate of group 0 to 1.0000e-02.
Test set: Average loss: 0.6023, Accuracy: 7891/10000 (78.91%)
Epoch 16
Train: Loss=0.5817 Batch_id=390 Accuracy=81.55: 100%|██████████| 391/391 [00:19<00:00, 19.71it/s]Adjusting learning rate of group 0 to 1.0000e-03.
Test set: Average loss: 0.6014, Accuracy: 7911/10000 (79.11%)
Epoch 17
Train: Loss=0.4692 Batch_id=390 Accuracy=82.18: 100%|██████████| 391/391 [00:19<00:00, 19.98it/s]Adjusting learning rate of group 0 to 1.0000e-03.
Test set: Average loss: 0.5913, Accuracy: 7956/10000 (79.56%)
Epoch 18
Train: Loss=0.6526 Batch_id=390 Accuracy=82.40: 100%|██████████| 391/391 [00:20<00:00, 18.86it/s]Adjusting learning rate of group 0 to 1.0000e-03.
Test set: Average loss: 0.5920, Accuracy: 7941/10000 (79.41%)
Epoch 19
Train: Loss=0.6541 Batch_id=390 Accuracy=82.61: 100%|██████████| 391/391 [00:20<00:00, 18.81it/s]Adjusting learning rate of group 0 to 1.0000e-03.
Test set: Average loss: 0.5910, Accuracy: 7960/10000 (79.60%)
Epoch 20
Train: Loss=0.6497 Batch_id=390 Accuracy=82.59: 100%|██████████| 391/391 [00:20<00:00, 19.21it/s]Adjusting learning rate of group 0 to 1.0000e-03.
Test set: Average loss: 0.5914, Accuracy: 7939/10000 (79.39%)
Train/Test Visualization
10 Mis-classified Images

2) Group Normalization
Model Architecture

----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 16, 32, 32] 432
ReLU-2 [-1, 16, 32, 32] 0
GroupNorm-3 [-1, 16, 32, 32] 32
Dropout-4 [-1, 16, 32, 32] 0
Conv2d-5 [-1, 32, 32, 32] 4,608
ReLU-6 [-1, 32, 32, 32] 0
GroupNorm-7 [-1, 32, 32, 32] 64
Dropout-8 [-1, 32, 32, 32] 0
Conv2d-9 [-1, 16, 32, 32] 512
MaxPool2d-10 [-1, 16, 16, 16] 0
Conv2d-11 [-1, 24, 16, 16] 3,456
ReLU-12 [-1, 24, 16, 16] 0
GroupNorm-13 [-1, 24, 16, 16] 48
Dropout-14 [-1, 24, 16, 16] 0
Conv2d-15 [-1, 28, 16, 16] 6,048
ReLU-16 [-1, 28, 16, 16] 0
GroupNorm-17 [-1, 28, 16, 16] 56
Dropout-18 [-1, 28, 16, 16] 0
Conv2d-19 [-1, 32, 16, 16] 8,064
ReLU-20 [-1, 32, 16, 16] 0
GroupNorm-21 [-1, 32, 16, 16] 64
Dropout-22 [-1, 32, 16, 16] 0
Conv2d-23 [-1, 16, 16, 16] 512
MaxPool2d-24 [-1, 16, 8, 8] 0
Conv2d-25 [-1, 20, 8, 8] 2,880
ReLU-26 [-1, 20, 8, 8] 0
GroupNorm-27 [-1, 20, 8, 8] 40
Dropout-28 [-1, 20, 8, 8] 0
Conv2d-29 [-1, 28, 8, 8] 5,040
ReLU-30 [-1, 28, 8, 8] 0
GroupNorm-31 [-1, 28, 8, 8] 56
Dropout-32 [-1, 28, 8, 8] 0
Conv2d-33 [-1, 32, 8, 8] 8,064
ReLU-34 [-1, 32, 8, 8] 0
GroupNorm-35 [-1, 32, 8, 8] 64
Dropout-36 [-1, 32, 8, 8] 0
AvgPool2d-37 [-1, 32, 1, 1] 0
Conv2d-38 [-1, 10, 1, 1] 320
================================================================
Total params: 40,360
Trainable params: 40,360
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 2.51
Params size (MB): 0.15
Estimated Total Size (MB): 2.67
----------------------------------------------------------------
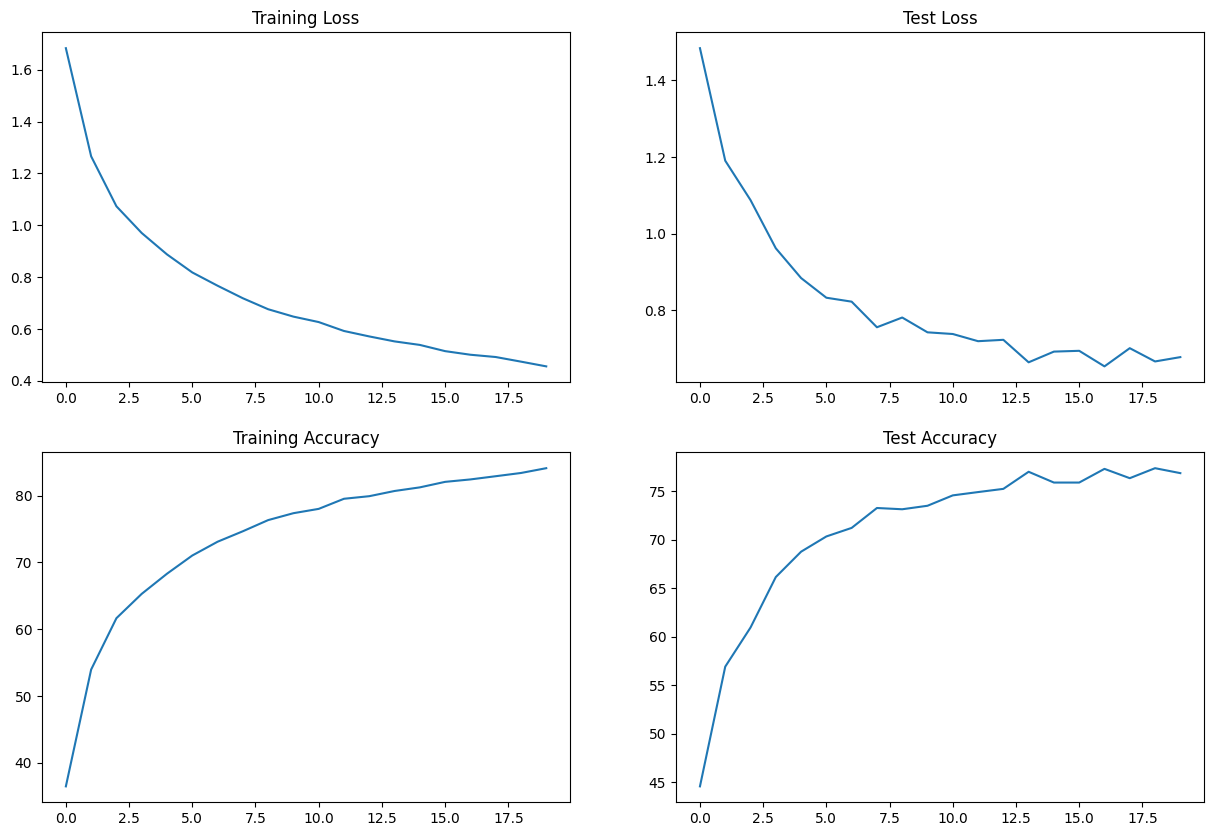
Results:
- Best Train Accuracy - 84.09%
- Best Test Accuracy - 77.35%
- Test Accuracy - 76.84%
- Total Parameters - 40,360
Train/Test Logs
Epoch 1
Train: Loss=1.5306 Batch_id=390 Accuracy=36.48: 100%|██████████| 391/391 [00:20<00:00, 19.48it/s]
Test set: Average loss: 1.4840, Accuracy: 4458/10000 (44.58%)
Epoch 2
Train: Loss=1.2313 Batch_id=390 Accuracy=53.96: 100%|██████████| 391/391 [00:19<00:00, 20.47it/s]
Test set: Average loss: 1.1905, Accuracy: 5691/10000 (56.91%)
Epoch 3
Train: Loss=0.9978 Batch_id=390 Accuracy=61.65: 100%|██████████| 391/391 [00:18<00:00, 20.66it/s]
Test set: Average loss: 1.0877, Accuracy: 6094/10000 (60.94%)
Epoch 4
Train: Loss=0.8820 Batch_id=390 Accuracy=65.29: 100%|██████████| 391/391 [00:19<00:00, 20.15it/s]
Test set: Average loss: 0.9620, Accuracy: 6614/10000 (66.14%)
Epoch 5
Train: Loss=0.9931 Batch_id=390 Accuracy=68.30: 100%|██████████| 391/391 [00:19<00:00, 19.57it/s]
Test set: Average loss: 0.8844, Accuracy: 6875/10000 (68.75%)
Epoch 6
Train: Loss=1.0570 Batch_id=390 Accuracy=71.02: 100%|██████████| 391/391 [00:19<00:00, 19.60it/s]
Test set: Average loss: 0.8330, Accuracy: 7032/10000 (70.32%)
Epoch 7
Train: Loss=0.6323 Batch_id=390 Accuracy=73.09: 100%|██████████| 391/391 [00:20<00:00, 19.55it/s]
Test set: Average loss: 0.8228, Accuracy: 7120/10000 (71.20%)
Epoch 8
Train: Loss=0.5310 Batch_id=390 Accuracy=74.65: 100%|██████████| 391/391 [00:19<00:00, 20.25it/s]
Test set: Average loss: 0.7560, Accuracy: 7325/10000 (73.25%)
Epoch 9
Train: Loss=0.7021 Batch_id=390 Accuracy=76.32: 100%|██████████| 391/391 [00:19<00:00, 20.39it/s]
Test set: Average loss: 0.7814, Accuracy: 7312/10000 (73.12%)
Epoch 10
Train: Loss=0.6399 Batch_id=390 Accuracy=77.36: 100%|██████████| 391/391 [00:19<00:00, 19.74it/s]
Test set: Average loss: 0.7428, Accuracy: 7348/10000 (73.48%)
Epoch 11
Train: Loss=0.6346 Batch_id=390 Accuracy=78.00: 100%|██████████| 391/391 [00:20<00:00, 19.43it/s]
Test set: Average loss: 0.7384, Accuracy: 7455/10000 (74.55%)
Epoch 12
Train: Loss=0.4105 Batch_id=390 Accuracy=79.51: 100%|██████████| 391/391 [00:20<00:00, 19.22it/s]
Test set: Average loss: 0.7197, Accuracy: 7489/10000 (74.89%)
Epoch 13
Train: Loss=0.6398 Batch_id=390 Accuracy=79.90: 100%|██████████| 391/391 [00:19<00:00, 20.23it/s]
Test set: Average loss: 0.7232, Accuracy: 7522/10000 (75.22%)
Epoch 14
Train: Loss=0.5218 Batch_id=390 Accuracy=80.68: 100%|██████████| 391/391 [00:19<00:00, 20.28it/s]
Test set: Average loss: 0.6646, Accuracy: 7698/10000 (76.98%)
Epoch 15
Train: Loss=0.4599 Batch_id=390 Accuracy=81.22: 100%|██████████| 391/391 [00:19<00:00, 20.27it/s]
Test set: Average loss: 0.6925, Accuracy: 7587/10000 (75.87%)
Epoch 16
Train: Loss=0.5416 Batch_id=390 Accuracy=82.04: 100%|██████████| 391/391 [00:20<00:00, 19.32it/s]
Test set: Average loss: 0.6946, Accuracy: 7587/10000 (75.87%)
Epoch 17
Train: Loss=0.4043 Batch_id=390 Accuracy=82.41: 100%|██████████| 391/391 [00:20<00:00, 19.29it/s]
Test set: Average loss: 0.6540, Accuracy: 7728/10000 (77.28%)
Epoch 18
Train: Loss=0.5031 Batch_id=390 Accuracy=82.89: 100%|██████████| 391/391 [00:20<00:00, 19.13it/s]
Test set: Average loss: 0.7014, Accuracy: 7632/10000 (76.32%)
Epoch 19
Train: Loss=0.3903 Batch_id=390 Accuracy=83.37: 100%|██████████| 391/391 [00:19<00:00, 19.74it/s]
Test set: Average loss: 0.6668, Accuracy: 7735/10000 (77.35%)
Epoch 20
Train: Loss=0.4610 Batch_id=390 Accuracy=84.09: 100%|██████████| 391/391 [00:19<00:00, 19.68it/s]
Test set: Average loss: 0.6781, Accuracy: 7684/10000 (76.84%)
Train/Test Visualization
10 Mis-classified Images

3) Layer Normalization
Model Architecture

----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 8, 30, 30] 216
ReLU-2 [-1, 8, 30, 30] 0
LayerNorm-3 [-1, 8, 30, 30] 14,400
Dropout-4 [-1, 8, 30, 30] 0
Conv2d-5 [-1, 10, 28, 28] 720
ReLU-6 [-1, 10, 28, 28] 0
LayerNorm-7 [-1, 10, 28, 28] 15,680
Dropout-8 [-1, 10, 28, 28] 0
Conv2d-9 [-1, 8, 28, 28] 80
MaxPool2d-10 [-1, 8, 14, 14] 0
Conv2d-11 [-1, 10, 14, 14] 720
ReLU-12 [-1, 10, 14, 14] 0
LayerNorm-13 [-1, 10, 14, 14] 3,920
Dropout-14 [-1, 10, 14, 14] 0
Conv2d-15 [-1, 12, 14, 14] 1,080
ReLU-16 [-1, 12, 14, 14] 0
LayerNorm-17 [-1, 12, 14, 14] 4,704
Dropout-18 [-1, 12, 14, 14] 0
Conv2d-19 [-1, 14, 14, 14] 1,512
ReLU-20 [-1, 14, 14, 14] 0
LayerNorm-21 [-1, 14, 14, 14] 5,488
Dropout-22 [-1, 14, 14, 14] 0
Conv2d-23 [-1, 8, 14, 14] 112
MaxPool2d-24 [-1, 8, 7, 7] 0
Conv2d-25 [-1, 10, 7, 7] 720
ReLU-26 [-1, 10, 7, 7] 0
LayerNorm-27 [-1, 10, 7, 7] 980
Dropout-28 [-1, 10, 7, 7] 0
Conv2d-29 [-1, 12, 7, 7] 1,080
ReLU-30 [-1, 12, 7, 7] 0
LayerNorm-31 [-1, 12, 7, 7] 1,176
Dropout-32 [-1, 12, 7, 7] 0
Conv2d-33 [-1, 14, 7, 7] 1,512
ReLU-34 [-1, 14, 7, 7] 0
LayerNorm-35 [-1, 14, 7, 7] 1,372
Dropout-36 [-1, 14, 7, 7] 0
AvgPool2d-37 [-1, 14, 1, 1] 0
Conv2d-38 [-1, 10, 1, 1] 140
================================================================
Total params: 55,612
Trainable params: 55,612
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 0.80
Params size (MB): 0.21
Estimated Total Size (MB): 1.03
----------------------------------------------------------------
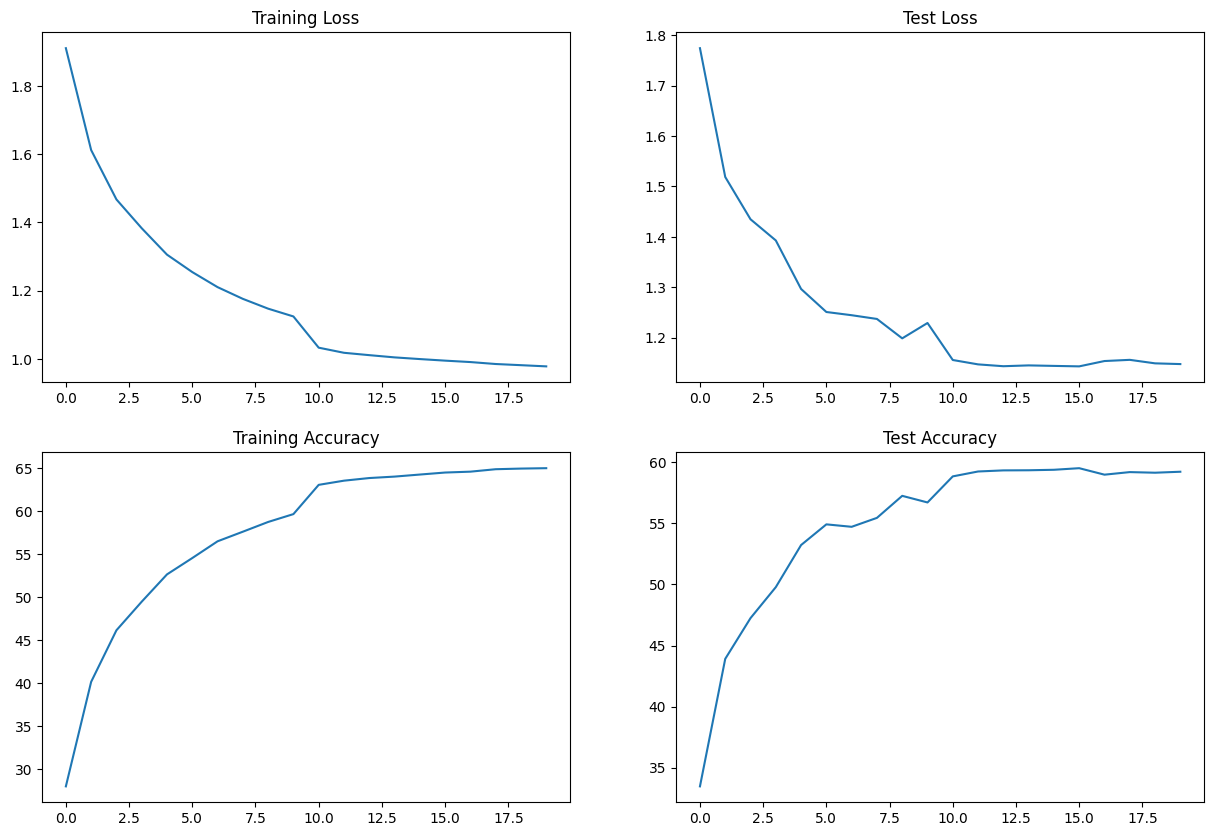
Results:
- Best Train Accuracy - 76.42%
- Best Test Accuracy - 68.48%
- Test Accuracy - 68.48%
- Total Parameters - 55,612
Train/Test Logs
Adjusting learning rate of group 0 to 1.0000e-01.
Epoch 1
Train: Loss=1.5604 Batch_id=390 Accuracy=27.79: 100%|██████████| 391/391 [00:20<00:00, 19.18it/s]Adjusting learning rate of group 0 to 1.0000e-01.
Test set: Average loss: 1.6360, Accuracy: 3908/10000 (39.08%)
Epoch 2
Train: Loss=1.2691 Batch_id=390 Accuracy=44.53: 100%|██████████| 391/391 [00:20<00:00, 18.70it/s]Adjusting learning rate of group 0 to 1.0000e-01.
Test set: Average loss: 1.4476, Accuracy: 4765/10000 (47.65%)
Epoch 3
Train: Loss=1.2596 Batch_id=390 Accuracy=52.46: 100%|██████████| 391/391 [00:19<00:00, 20.09it/s]Adjusting learning rate of group 0 to 1.0000e-01.
Test set: Average loss: 1.2390, Accuracy: 5554/10000 (55.54%)
Epoch 4
Train: Loss=1.1582 Batch_id=390 Accuracy=57.66: 100%|██████████| 391/391 [00:19<00:00, 19.94it/s]Adjusting learning rate of group 0 to 1.0000e-01.
Test set: Average loss: 1.1633, Accuracy: 5809/10000 (58.09%)
Epoch 5
Train: Loss=0.9210 Batch_id=390 Accuracy=61.32: 100%|██████████| 391/391 [00:19<00:00, 20.07it/s]Adjusting learning rate of group 0 to 1.0000e-01.
Test set: Average loss: 1.0992, Accuracy: 6061/10000 (60.61%)
Epoch 6
Train: Loss=1.0223 Batch_id=390 Accuracy=63.65: 100%|██████████| 391/391 [00:19<00:00, 19.58it/s]Adjusting learning rate of group 0 to 1.0000e-01.
Test set: Average loss: 1.1038, Accuracy: 6042/10000 (60.42%)
Epoch 7
Train: Loss=0.9897 Batch_id=390 Accuracy=65.52: 100%|██████████| 391/391 [00:19<00:00, 19.62it/s]Adjusting learning rate of group 0 to 1.0000e-01.
Test set: Average loss: 1.0206, Accuracy: 6353/10000 (63.53%)
Epoch 8
Train: Loss=0.8556 Batch_id=390 Accuracy=67.30: 100%|██████████| 391/391 [00:19<00:00, 19.91it/s]Adjusting learning rate of group 0 to 1.0000e-01.
Test set: Average loss: 0.9880, Accuracy: 6479/10000 (64.79%)
Epoch 9
Train: Loss=1.0066 Batch_id=390 Accuracy=68.71: 100%|██████████| 391/391 [00:19<00:00, 20.25it/s]Adjusting learning rate of group 0 to 1.0000e-01.
Test set: Average loss: 0.9711, Accuracy: 6535/10000 (65.35%)
Epoch 10
Train: Loss=0.7505 Batch_id=390 Accuracy=69.90: 100%|██████████| 391/391 [00:19<00:00, 20.48it/s]Adjusting learning rate of group 0 to 1.0000e-02.
Test set: Average loss: 0.9523, Accuracy: 6605/10000 (66.05%)
Epoch 11
Train: Loss=0.7378 Batch_id=390 Accuracy=73.83: 100%|██████████| 391/391 [00:19<00:00, 19.91it/s]Adjusting learning rate of group 0 to 1.0000e-02.
Test set: Average loss: 0.9037, Accuracy: 6799/10000 (67.99%)
Epoch 12
Train: Loss=0.8557 Batch_id=390 Accuracy=74.50: 100%|██████████| 391/391 [00:20<00:00, 19.35it/s]Adjusting learning rate of group 0 to 1.0000e-02.
Test set: Average loss: 0.9033, Accuracy: 6827/10000 (68.27%)
Epoch 13
Train: Loss=0.6750 Batch_id=390 Accuracy=74.85: 100%|██████████| 391/391 [00:20<00:00, 19.53it/s]Adjusting learning rate of group 0 to 1.0000e-02.
Test set: Average loss: 0.9049, Accuracy: 6826/10000 (68.26%)
Epoch 14
Train: Loss=0.6658 Batch_id=390 Accuracy=75.02: 100%|██████████| 391/391 [00:19<00:00, 20.19it/s]Adjusting learning rate of group 0 to 1.0000e-02.
Test set: Average loss: 0.9070, Accuracy: 6815/10000 (68.15%)
Epoch 15
Train: Loss=0.6038 Batch_id=390 Accuracy=75.38: 100%|██████████| 391/391 [00:18<00:00, 20.60it/s]Adjusting learning rate of group 0 to 1.0000e-02.
Test set: Average loss: 0.9041, Accuracy: 6832/10000 (68.32%)
Epoch 16
Train: Loss=0.5226 Batch_id=390 Accuracy=75.62: 100%|██████████| 391/391 [00:19<00:00, 20.31it/s]Adjusting learning rate of group 0 to 1.0000e-02.
Test set: Average loss: 0.9062, Accuracy: 6811/10000 (68.11%)
Epoch 17
Train: Loss=0.5457 Batch_id=390 Accuracy=75.79: 100%|██████████| 391/391 [00:20<00:00, 19.51it/s]Adjusting learning rate of group 0 to 1.0000e-02.
Test set: Average loss: 0.9070, Accuracy: 6822/10000 (68.22%)
Epoch 18
Train: Loss=0.7538 Batch_id=390 Accuracy=75.95: 100%|██████████| 391/391 [00:19<00:00, 19.68it/s]Adjusting learning rate of group 0 to 1.0000e-02.
Test set: Average loss: 0.9090, Accuracy: 6838/10000 (68.38%)
Epoch 19
Train: Loss=0.6772 Batch_id=390 Accuracy=76.19: 100%|██████████| 391/391 [00:19<00:00, 20.18it/s]Adjusting learning rate of group 0 to 1.0000e-02.
Test set: Average loss: 0.9156, Accuracy: 6814/10000 (68.14%)
Epoch 20
Train: Loss=0.5566 Batch_id=390 Accuracy=76.42: 100%|██████████| 391/391 [00:18<00:00, 20.65it/s]Adjusting learning rate of group 0 to 1.0000e-03.
Test set: Average loss: 0.9115, Accuracy: 6848/10000 (68.48%)
Train/Test Visualization
10 Mis-classified Images
