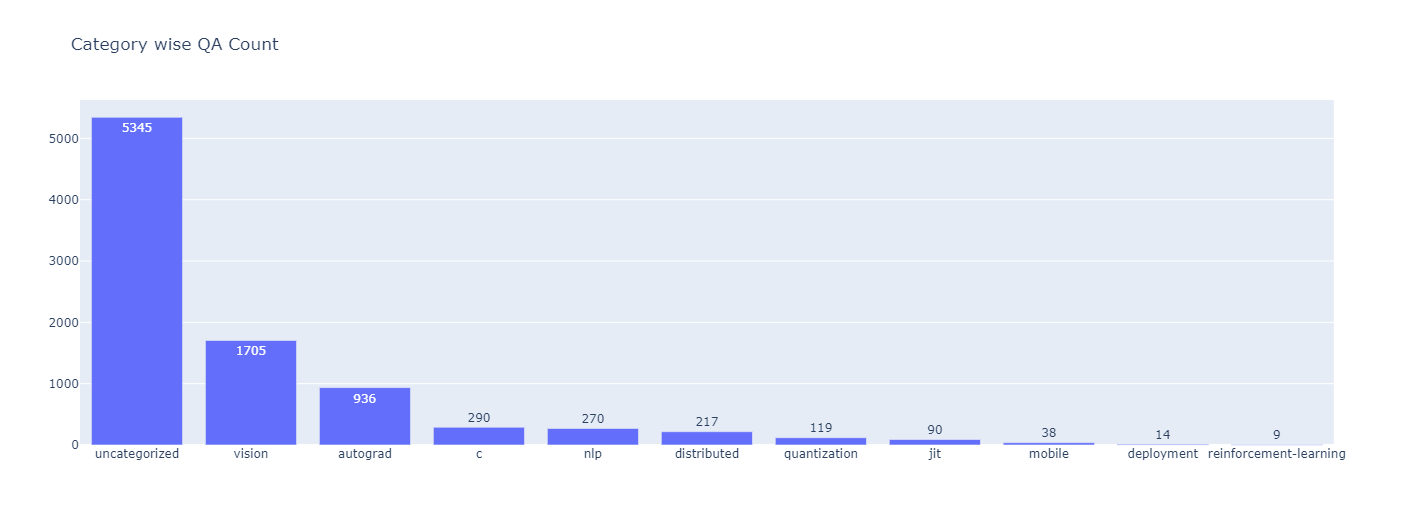
Pytorch Discuss QA Dataset
| Data Formats | Data Size |
|---|---|
| JSON , Excel | 23.923 MB |
This dataset contains solved questions and answers from Pytorch Discuss.
Description
The dataset is in JSON format. It has 9,033 entries. It consist of:
| Property | Description |
|---|---|
| id | Unique Pytorch Discuss ID |
| source | The source of question and answer which is "pytorch_discuss" in our case |
| url | Link of query post |
| query | Question |
| solution | Answer for the specified quest |
| solution_has_code | True if solution has code otherwise, False |
| query_has_code | True if query has code otherwise, False |
| category | The category to which the question belongs |
| intent | the question title |
Sample Data
[
{
"pytorch_discuss_id": 61598,
"source": "pytorch_discuss",
"url": "https://discuss.pytorch.org/t/pytorch-dqn-tutorial-where-is-autograd/23460",
"query": "<p><a href=\"https://pytorch.org/tutorials/intermediate/reinforcement_q_learning.html\" class=\"onebox\" target=\"_blank\" rel=\"nofollow noopener\">https://pytorch.org/tutorials/intermediate/reinforcement_q_learning.html</a></p>\n<p>while the comments in the tutorial specify that autograd is used, it is never explicitly declared (that I can see). In supervised learning, the inputs are usually set as input_data = Variable(input_data) and then out = net.forward(data). However, here, Variable is never used. I do see that the loss tensor contains a gradient - but I am not sure where this came from.</p>\n<p>Another observation, if I set<br>\nstate_action_values = Variable(state_action_values,requires_grad=True)<br>\nthen the code will not run - throwing an error on:<br>\nfor param in policy_net.parameters():<br>\nparam.grad.data.clamp_(-1, 1)</p>\n<p>saying that ‘NoneType’ has no attribute data (where as clearly before adding the Variable code it did…)</p>\n<p>Any ideas? Why is Variable not necessary here?</p>",
"solution": "<p>I haven’t explored the tutorial in detail, but from what I know <code>state_action_values</code> are the output of the model, and should already require gradients.<br>\nCould you check it with <code>state_action_values.requires_grad</code>?</p>\n<p>Also, if you re-wrap a <code>Tensor</code>, it will lose it’s associated computation graph and you are thus detaching it.<br>\nThat’s the reason, why <code>.grad</code> is empty in the example you’ve posted.</p>",
"solution_has_code": true,
"query_has_code": false,
"category": "reinforcement-learning",
"intent": "pytorch dqn tutorial where is autograd"
},
{
"pytorch_discuss_id": 22771,
"source": "pytorch_discuss",
"url": "https://discuss.pytorch.org/t/reinforce-deprecated/9325",
"query": "<p>I’ve being using action.reinforce(reward) for policy gradient based training, but it seems like there’s been a change recently and I get an error stating:</p>\n<p>File “/opt/conda/envs/pytorch-py35/lib/python3.5/site-packages/torch/autograd/variable.py”, line 209, in reinforce<br>\nif not isinstance(self.grad_fn, StochasticFunction):<br>\nNameError: name ‘StochasticFunction’ is not defined</p>\n<p>I read <a href=\"https://github.com/pytorch/pytorch/issues/3340\" rel=\"nofollow noopener\">on github</a> that .reinforce is being deprecated, and it’s suggested to use torch.distributions.</p>\n<p>Is there a reason for this change? Reinforce seemed relatively simple and intuitive. It’ll be great if the <a href=\"https://github.com/pytorch/examples/blob/master/reinforcement_learning/reinforce.py\" rel=\"nofollow noopener\">reinforce example from pytorch</a> is updated to reflect this change.</p>",
"solution": "<p>If you are on the 0.2 release, <code>reinforce</code> is still available. If you’re on <code>master</code> and have <code>torch.distributions</code> instead, the RL examples should now be as follows: <a href=\"https://github.com/pytorch/examples/pull/249\" rel=\"nofollow noopener\">https://github.com/pytorch/examples/pull/249</a></p>\n<p><code>torch.distributions</code> is much more general and suitable for a larger range of tasks - building the equivalent of <code>reinforce</code> using this is relatively simple (and arguably cleaner as it can be used to create a normal loss function to backpropagate).</p>",
"solution_has_code": true,
"query_has_code": false,
"category": "reinforcement-learning",
"intent": "reinforce deprecated"
}
]